
Node Sources Overview
Node Sources Overview
What is a Node Source?
A Node Source (also referenced as Resource Model Source in some docs) is a way to share information about your infrastructure to Rundeck as Nodes.
Sources for Node data are commonly third-party systems such as Amazon EC2 or ServiceNow CMBD, accessed through their API, but could also be static files or scripts maintained specifically for this purpose. Some data providers can be accessed directly from the automation interface using the Resource Editor.
Adding Nodes to a Project
To add Nodes to a project, add one or more Node Sources to a project
- Click the Project Settings gear at the bottom left, then Edit Nodes
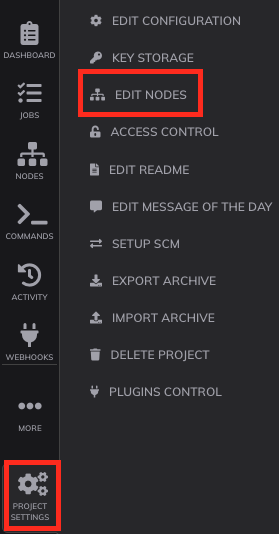
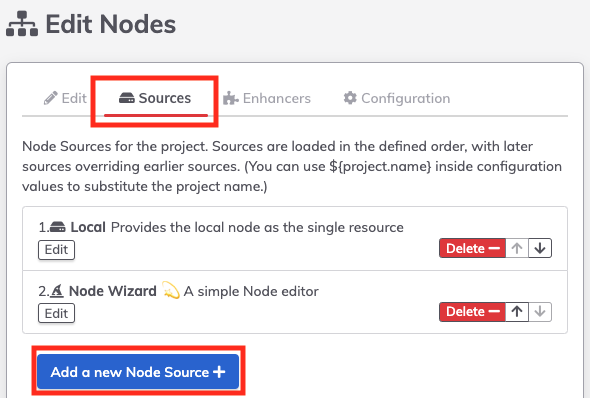
- Under Edit Nodes, select Sources and Add a new Node Source+
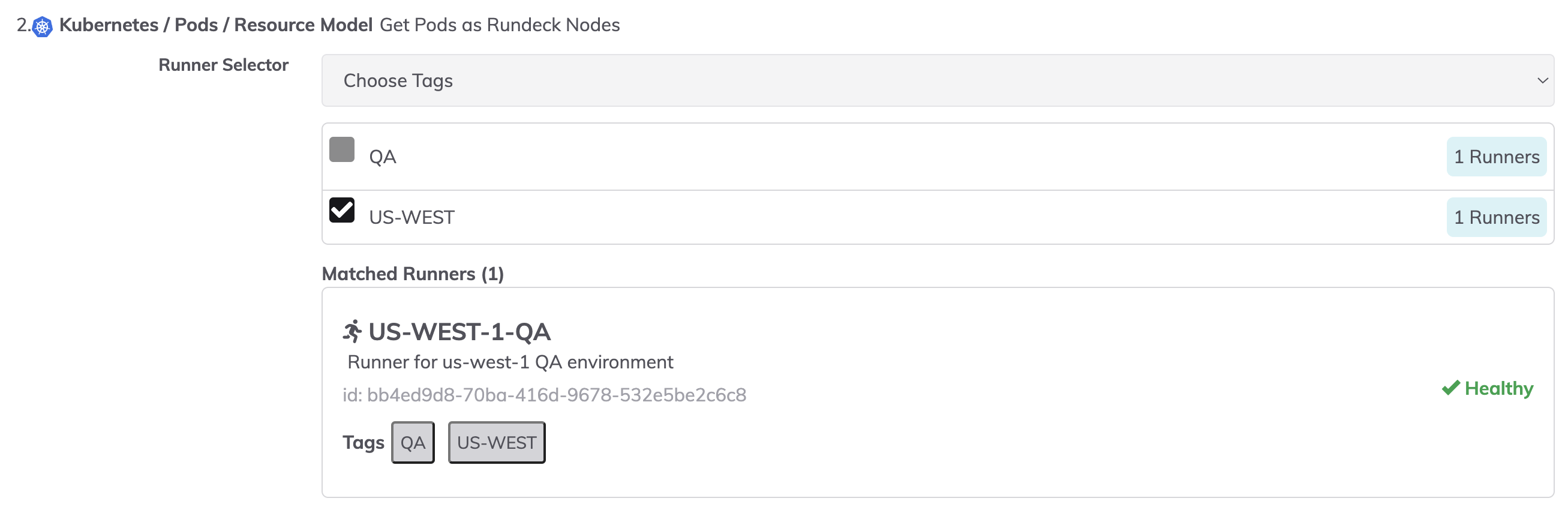
- If using an Enterprise Runner to discover nodes, then select the appropriate Runner Tag using the Runner Selector:
As of version 4.16.0, the following Node Sources are available to use through the Enterprise Runner:
- Ansible Inventory
- VMware
- Kubernetes
- Docker
- File
- Script
When to use a Runner
Use a remote Enterprise Runner when the node inventory is not directly accessible by Runbook Automation. For Example, if the node inventory is stored in an Ansible Inventory file, or is available from the vSphere API, but Runbook Automation does not have direct access to these endpoints, then an Enterprise Runner is the recommended mode of discovery.
Node Sources Available on Runner
If a Node Source is selected that is not in the list above, the following error will appear after the node source tries to gather resources: Reason: The datadog-resource-model plugin was not found on Runner ID = US-WEST-1-QA. You may need to upgrade your Runner or select a different Runner. In a future version the Node Source configuration will dynamically know which runners support which Node Source plugins.
Node Source Data Formats
Rundeck makes use of common data formats (XML, JSON & YAML). Though third-party software may produce these formats natively, it is typical to have to massage the output of one system into the appropriate format to be consumed by Rundeck. Since URLs and HTTP are a lowest-common-denominator for communication, Rundeck only requires that the data Providers make this data available as a file at a URL or on the local disk.
Managing nodes with mixed Operating Systems
How do mixed nodes work in a project?
The servers and devices that are managed by Rundeck (or PagerDuty Runbook Automation) are referred to as nodes. Those nodes have some individual attributes that will be unique and other attributes that can be designated per project. In any case where a node has a unique value for an attribute, that overrides an existing project default value. A project configuration has a default node executor and file copier applicable for all project nodes. This is effective if all nodes are using the same auth/network protocol like SSH or WinRM. However, some environments are built with mixed operating systems including Linux, UNIX, and Windows. In an environment with mixed operating systems, some jobs and commands can run in both environments.
Nodes are defined in each project and can be configured or defined in various ways. Ideally, most or all nodes will come from a dynamic node model source, such as Amazon EC2 (Runbook Automation only) or Oracle Cloud Infrastructure. It is also possible to define nodes with a more static source such as a .yaml file or using the Node Wizard (Runbook Automation only).
An example XML source with mixed nodes
When defining a model source, a single default node executor and file copier is designated for the majority of nodes. For this example, that default is globally defined as SSH, SSHJ, or OpenSSH. After creating the project and defining the model source, this example overrides that default when adding definitions for a Windows-based target node. In the xml definition below, the node-executor and file-copier node attributes set specific default node executors and file copiers for the specific Windows node. Note that the Linux nodes don’t have those attributes because they get those from the default project settings. Each node with those attributes defined will override the project defaults.
<?xml version="1.0" encoding="UTF-8"?>
<project>
<node name="node00"
description="Linux Node 00"
tags="db"
hostname="192.168.56.20"
osArch="amd64"
osFamily="unix"
osName="Linux"
osVersion="3.10.0-1062.4.1.el7.x86_64"
username="vagrant"
ssh-key-storage-path="keys/rundeck" />
<node name="node01"
description="Linux Node 01"
tags="db"
hostname="192.168.56.21"
osArch="amd64"
osFamily="unix"
osName="Linux"
osVersion="3.10.0-1062.4.1.el7.x86_64"
username="vagrant"
ssh-key-storage-path="keys/rundeck" />
<node name="node02"
description="Linux Node 02"
tags="nas"
hostname="192.168.56.22"
osArch="amd64"
osFamily="unix"
osName="Linux"
osVersion="3.10.0-1062.4.1.el7.x86_64"
username="vagrant"
ssh-key-storage-path="keys/rundeck" />
<node name="windows"
description="Windows Server"
tags="ad"
hostname="192.168.56.23"
osArch="amd64"
osFamily="windows"
osName="Windows Server 2022"
osVersion="6.3"
username="rundeckuser"
winrm-password-storage-path="keys/windows.password"
winrm-authtype="basic"
node-executor="WinRMPython"
file-copier="WinRMcpPython"
/>
</project>
Based on this Node Source file, all commands/jobs dispatched to the Windows node should use the WinRMPython node executor and the rest of the nodes should use the default SSH node defined at the project level.