
What are the pieces of a job?
What are the pieces of a job?
The following elements are the essential parts of a Rundeck / Runbook Automation Job.
Job Identification information
The identification section of a job (labeled Details) is the first tab when defining a job.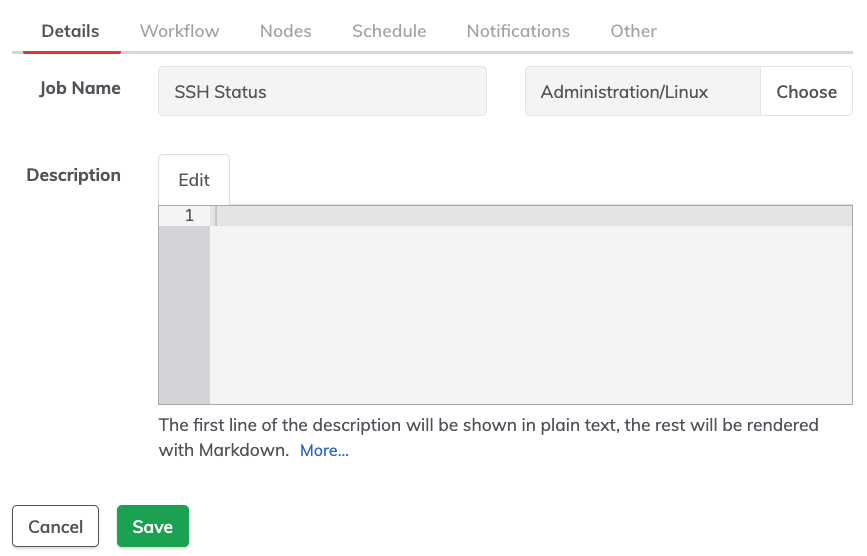
Job Name
The human-readable name. A good practice is to use a clear and descriptive name for the job, e.g: "Backup DB Servers".
Group
A Jobs group is a name (in the field to the right of the Job Name) that helps keep the jobs organized. Grouped Jobs should be shown within a directory (the group name). Groups can be defined by simply typing a name in the box or choosing an existing group by clicking the Choose button.
Description
The description helps others understand what this job does and when/how to use it.
If a job description contains more than one line of text, then the first line is used as the job description and the rest is accessible by clicking on the "more" link.
Workflow
The central piece that is thought of as the job, a workflow is a sequence of steps to be carried out. The steps could include commands, scripts, and/or specific actions. For example: deploying a Kubernetes pod, checking a service availability, etc.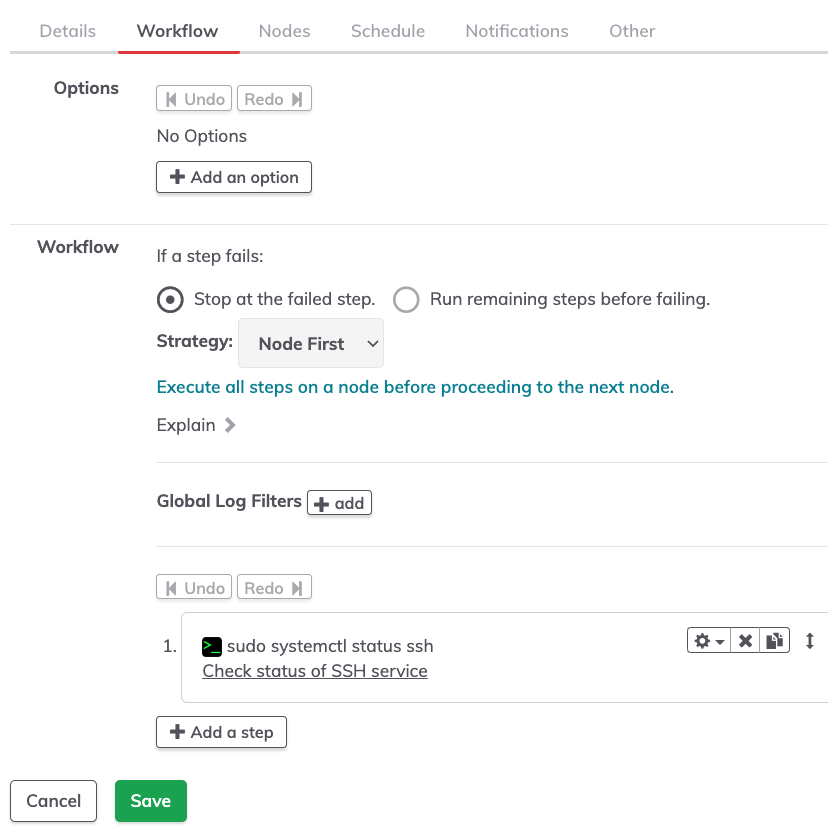
Workflows are a critical part of every Rundeck project. Essentially, the workflow is a series of steps to achieve any goal.
Options
Options are a central part of any workflow. Options are variables that can be either required or optional, offering a selection of choices presented to the user when they run a job. For example, when provisioning an AWS instance, the user may be prompted to select a specific region.
Users supply options by typing in a value or selecting from a menu of choices. A validation pattern ensures input complies with the option requirement. Once selected, the value chosen for the option is available to scripts and commands called by the Job.
Workflow Control Steps
Before getting to the actual steps, there are options that control what should happen if a step fails. There are also options for workflow strategy that can change the overall approach to steps and order they may be executed.
Global Log Filters and Job Step Log Filters
A log filter processes a workflow step's output, which may be transformed, given metadata for use by additional filters or renderers, or otherwise modified. At this point in the job definition, it is possible to add Global Log filters which process the whole job output. Later in the job definition, it’s possible to add Log Filter on individual job steps that would process only the step output. In either case (global or per job step), multiple log filters can be applied to the same sequence.
Steps
A step is the minimal Rundeck project element that does an action like a command, a script, an HTTP call, etc. A job might have just a single job step but usually, there will be multiple steps.
Workflow Steps vs Node Steps
When you create a job and add steps, you will see two different types of steps, Node Steps and Workflow Steps.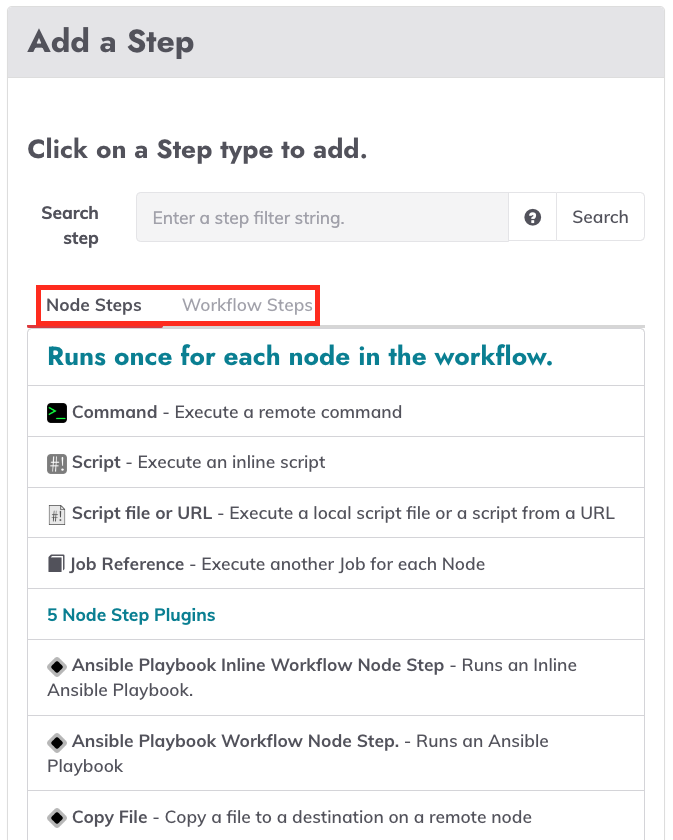
- Node steps are designed to be dispatched to one or more nodes based on a filter defined in the Nodes section. An example of a node step is a single command or an inline script to be executed on each targeted node.
- Workflow steps don't operate in a node context. Instead, these steps run on the local Rundeck server and run only once in a workflow. For example, the "Refresh Project Nodes" workflow step refreshes the Rundeck node cache in case of any change.
If there is a mix of node and workflow steps (which is common) the steps will be executed in order (based on the workflow strategy). Node steps may be executed several times, once per node, while the workflow steps will only run once.
Tips
If you have an idea of what step you are looking for, you can type text in the search field to narrow the list of steps you’ll see.
Nodes
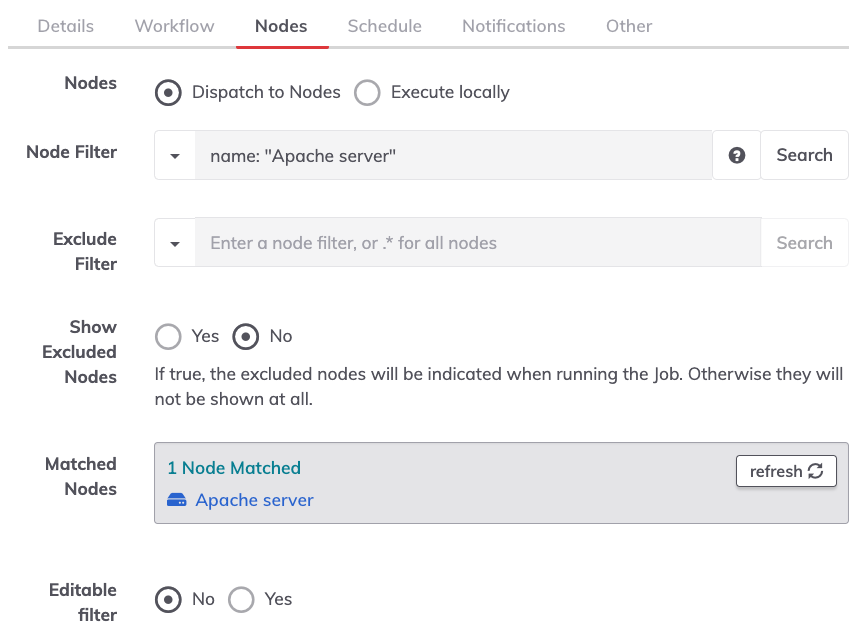
Node Dispatch
There are only two options available: dispatch to nodes and execute locally.
Using dispatch to nodes, the nodes to be targeted will be based on attributes in the node filter boxes.
Executing locally indicates that the automation server will be the only “node” targeted by the job.
Node Filter
Attributes and values entered here will be used to compose the filtered set of nodes to be targeted by the job. Any node attributes can be used for this purpose, including a combination of attributes and regular expressions if needed.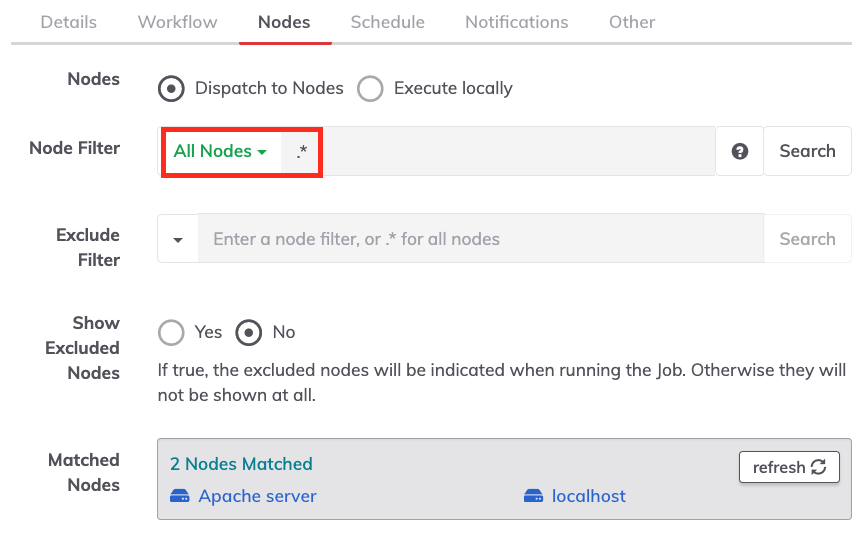
Exclude Filter
If anything is entered here, nodes that match this criteria are specifically excluded even if in the set generated by the node filter.
Show Excluded Nodes
If toggled to yes, this will specifically display which nodes were excluded by the exclude filter.
Matched Nodes
This box will display all nodes that match the node filter which helps to confirm that the filter is correct. If the filter has been changed, there is a refresh button.
Editable Filter
No by default, setting this to yes would allow users to change the node filter at run time if running the job directly. Users would be limited to nodes they have access to via ACL but it is usually simplest if the filter is not editable.
Other node Options
There are many other options below the main node filter but most are not used often. Details on each are available in the creating jobs page.
Schedule
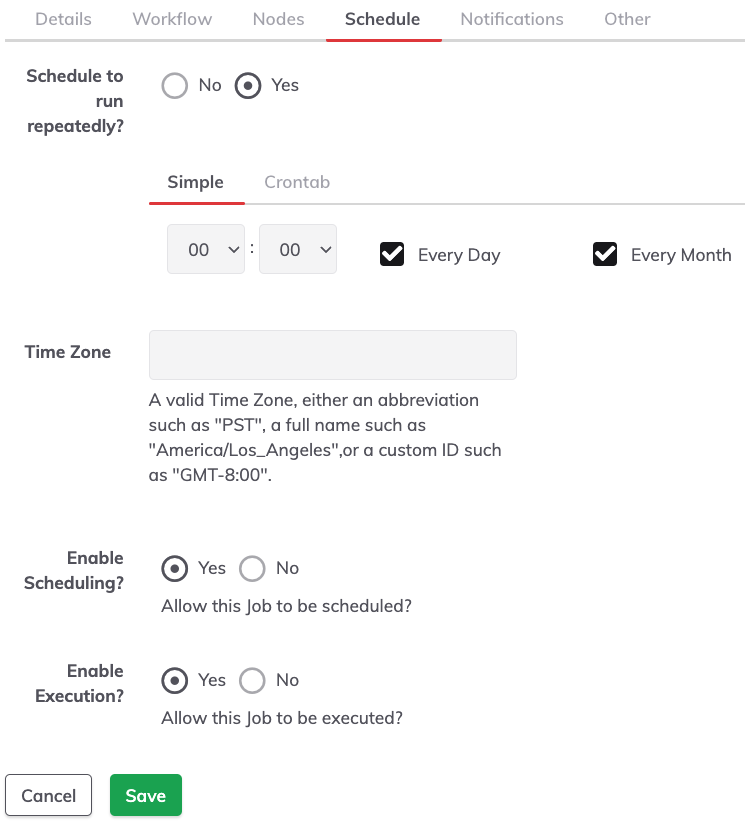
This defines the recurrent execution of a job. The schedule can be defined in the simple graphical chooser or Unix crontab format. This is optional, but extremely useful when you want to set up recurring jobs.
Schedule to run repeatedly
This defines the Schedule. Two options are available:
The Simple format (selecting the hours, days and months).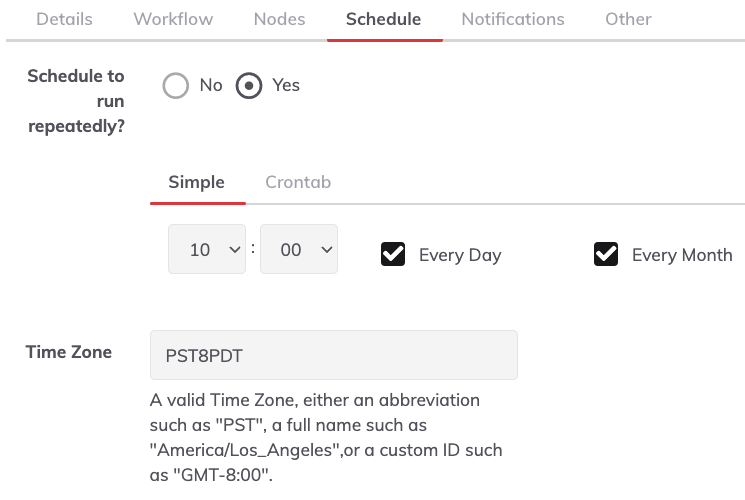
And the Crontab way to define the job scheduling following the Quartz Cron format.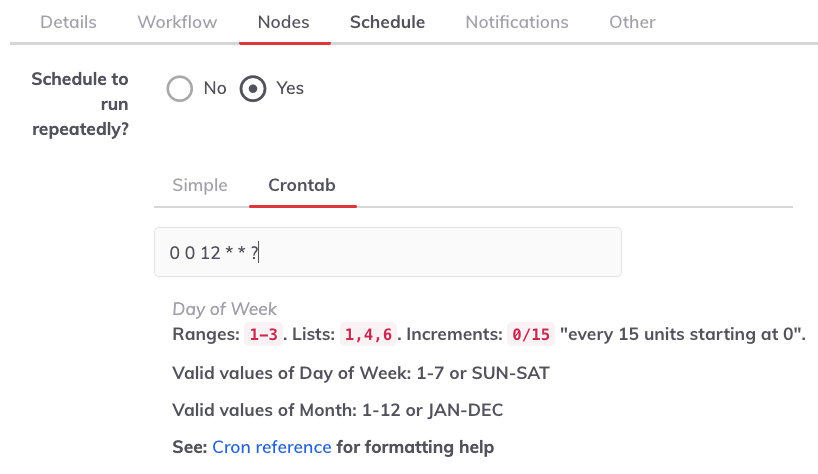
Timezone
This allows users to define a valid Time Zone, either an abbreviation such as "PST", a full name such as "America/Santiago",or a custom ID such as "GMT-4:00".
Enable Scheduling
This allows you to enable Job Scheduling.
Enable Execution
This allows you to enable and disable the Job Execution (scheduled or not).
Notifications
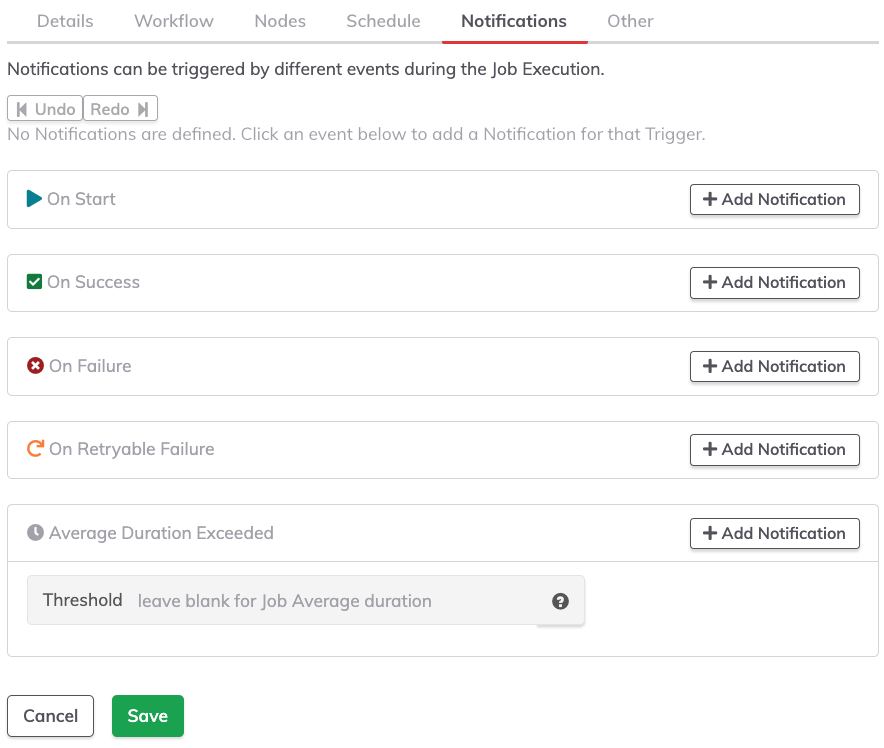
Job notifications are often overlooked. Notifications are messages such as an email or HTTP service push. This is a common area for integration with other tools since a notification could go to another tool when a job begins or when it fails. One or more notifications can be set for the notification events available.
Other configurations
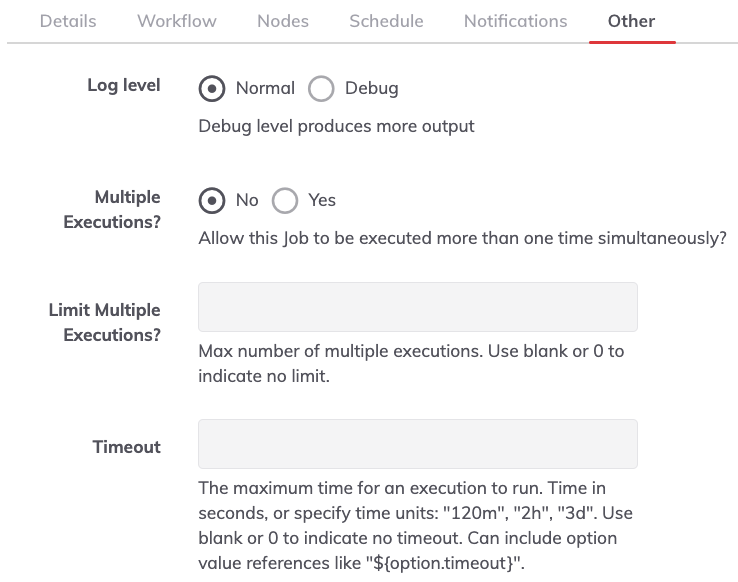
These options are generally related to job behavior.
Log Level
The ability to show only the job result ("Normal") or the detailed output ("Debug").
Multiple Executions and Limits to Multiple Executions
Multiple Executions provide users the ability to run a job multiple times at once. Otherwise, the Job can only have a single execution at a time (this is the default behavior).
The Limit Multiple Executions is the maximum number of multiple executions. Use blank or 0 to indicate no limit.
Job Timeout, Job Retry, and Retry Delay
Job timeout
Indicates the maximum runtime allowed for a job. After this time expires, the job will be aborted.
Job Retry
Count indicates the maximum number of times to retry the job if it fails or times out. You can also set a delay between retries.
Retry Delay
The time between a failed execution and a retry. Time in seconds, or specify time units: "120m", "2h", "3d".
Log Limits
These options can be used to limit how large the log for a specific job execution can become and what to do when the limit is reached.
Log Output Limit
Enter either the maximum total line count (e.g. "100"), maximum per-node line count ("100/node"), or maximum log file size ("100MB", "100KB", etc.), using "GB", "MB", "KB", "B" as Giga- Mega- Kilo- and bytes.
Log Limit Action
The action to perform if the output limit is reached.