# Result Data Plugins (Enterprise) [Incubating]
Available in Rundeck Enterprise
Incubating: this API or Feature may change in a future release.
Join us in the Rundeck Community Forums (opens new window) to talk more about it.
This plugin allows Jobs to export a JSON file as the result of an execution, which will be stored alongside the output log file. The JSON file can be retrieved via the API as JSON data, and shown in the GUI.
This allows a Job to be executed, and a JSON result returned, customized to contain data that is relevant to the outcome of the Job.
There are currently two different Plugins that can be used to produce JSON data for a Job.
# Requirements
TIP
Enable the incubating feature by adding the following configuration to Configuration Management or rundeck-config.properties
rundeck.feature.incubator.jobdata.enabled=true
# Plugin: Export Result Data
This plugin exports data groups from the Execution Context in the Global scope. Groups are named key-value maps.
The Execution Context is used to store data values as the Execution proceeds, and allows passing Captured data values from one step in a workflow to later steps in the workflow.
The captured data can be exported into a JSON file using the Export Data Execution Lifecycle Plugin.
Enable it in the Execution Lifecycle tab when editing the Job.
# Inputs
Data Groups
Define the set of Groups to export into the JSON data.
Typically data captured using the "Key Value Data" Log Filter plugin, is put in the data group, and values can be referenced via ${data.mydata}. That data is also usually captured in the Node Context. Use the "Global Variable" workflow step to copy values out of Node context into the Global context, specifying what Group to put the values in. When exporting data values to parent Jobs in a multi-job workflow, it needs to be put in the export group.
The default Group to export is export, but a different one or multiple ones can be specified using a comma-separated list such as data,export.
The JSON data will be exported in the same structure it has in the stored context, such as:
{
"export":{
"mydata": "mydata value"
}
}
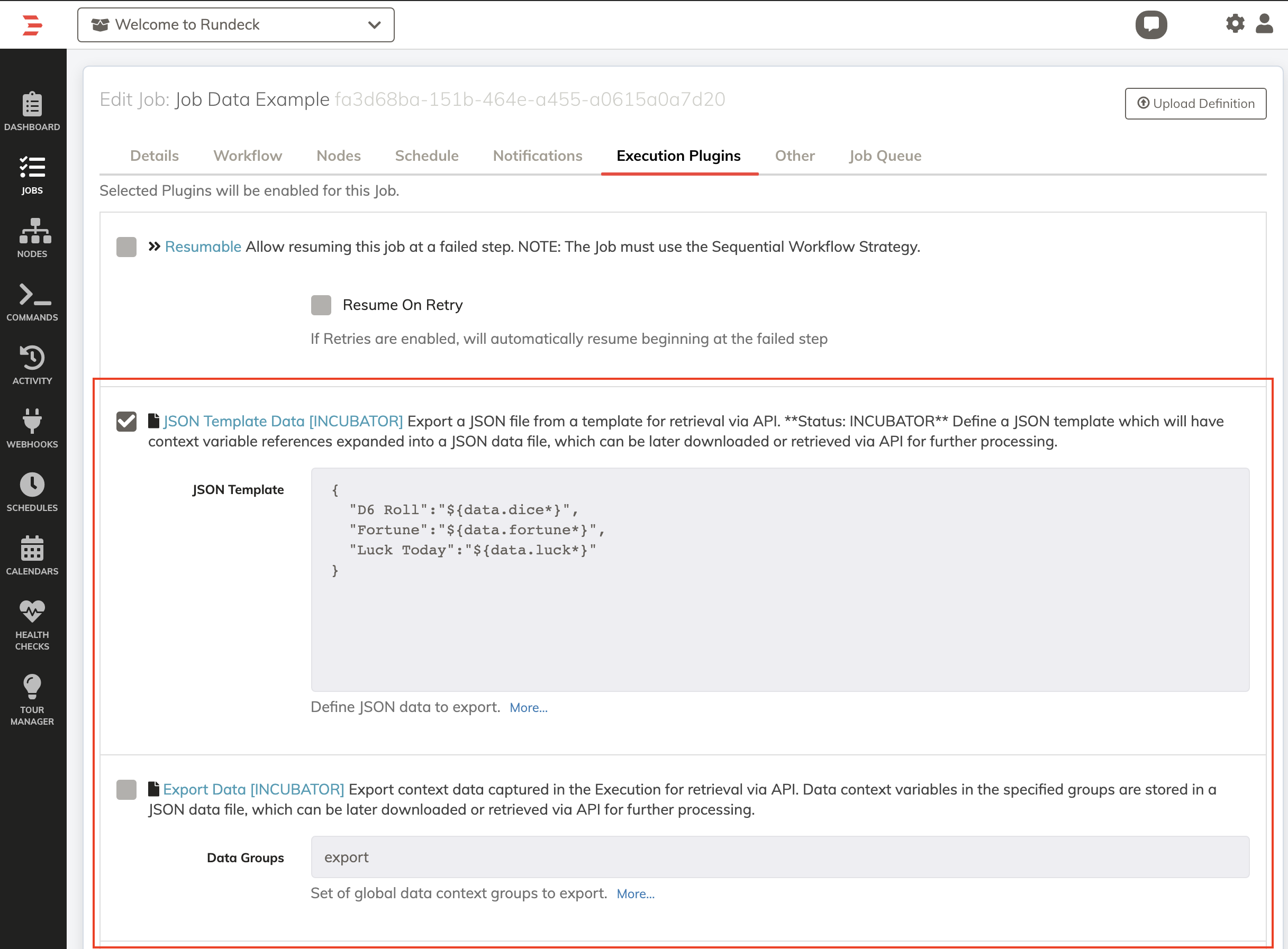
# Plugin: JSON Template Data
This plugin exports a JSON document that is generated from a template defined by the user.
Execution Context data values can be used within Strings within the JSON document, and will be expanded as usually done within Commands and other steps, such as ${data.myvalue}.
The JSON Template also supports a special syntax for generating Arrays or Objects of data, by iterating over either the Node or Step context values.
For example, data captured using the "Key Value Data" Log filter on a command or script executed multiple Nodes will have a value for each node that executed.
This data can be copied as an Array or JSON Object (keyed by Node name) into the output document.
A Regular expression filter of Node Name can also be used, or specific Steps selected.
# Inputs
JSON Template
Enter a valid JSON document.
# JSON Template format
Enter a valid JSON document. Context data values like ${data.name} or ${data.value@nodename} can be used within Strings.
Note that Context Variable expansion is evaluated in a global context, meaning that ${data.name} will only work if there is
a global value matching that group and name.
To include data captured from Node steps, such as when using the Key Value Data Log Filter, use a
syntax like ${data.name*} which will
collect all values for data.name in all Node contexts separated with a comma.
To expand all node values like that into a JSON array, use a special syntax:
{ "key": [], "key@": "data.name" }
This declares a map entry key as an array, and the key@ declares will collect all Node entries for data.name
into the key value.
The result will be:
{ "key": ["nodevalue1","nodevalue2"] }
To expand the data as a JSON Object instead, using Node Names as the map entries, declare the key entry
as a JSON object:
{ "key" : {}, "key@": "data.name" }
The result will be:
{ "key" : {"node1": "nodevalue1", "node2": "nodevalue2" } }
Select a subset of node values using a syntax after the @ sign in the key:
key@~REGEXmatches all nodes matching the regular expression
Similarly for Step values, select values based on the step key using this syntax:
*:keymatches all steps1:keyonly step 1 value
{ "key" : [], "*:key": "data.name" }
Results in key value being an array of all Step data values for data.name.
A combination of *:key@ will enumerate all step and node values if there are different values in different steps.
A value of 1:key@ will match all node values in step 1.
# API
After execution, get the JSON data produced by either of the plugins by sending a GET request to:
/api/36/project/$PROJECT/execution/$ID/result/data
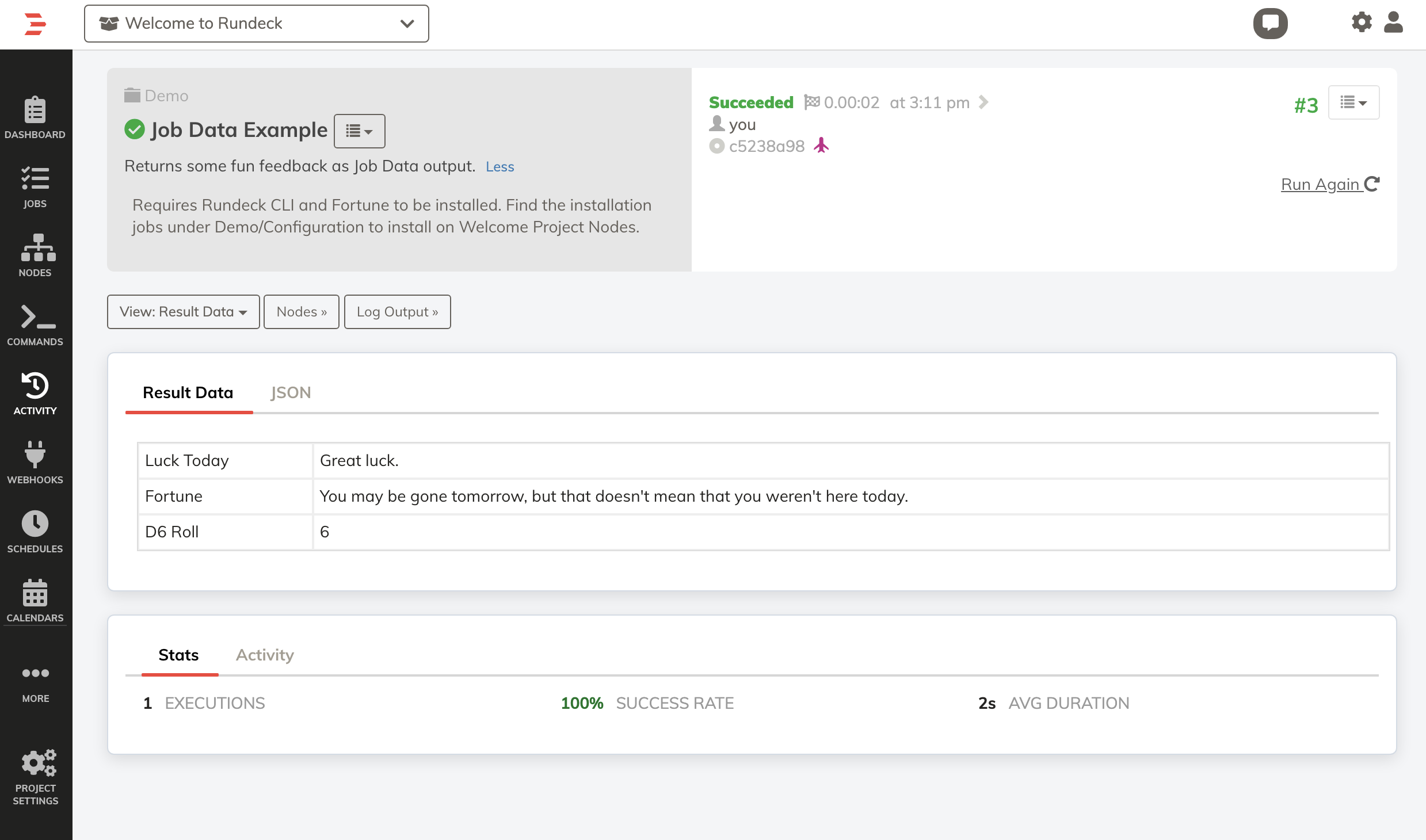
# Example Job
Here is a sample job provided in our Welcome Projects, that captures a set of values and uses the "JSON Template" plugin to export the JSON:
Note: This requires installation of Fortune and the Rundeck CLI. Be sure to enable the feature prior to importing the job definition.
- defaultTab: nodes
description: |-
Returns some fun feedback as data output.
Requires Rundeck CLI and Fortune to be installed. Find the installation jobs under Demo/Configuration
executionEnabled: true
group: Demo
loglevel: INFO
maxMultipleExecutions: '2'
multipleExecutions: true
name: Result Data Example
nodeFilterEditable: true
plugins:
ExecutionLifecycle:
json-data:
jsonTemplate: |-
{
"D6 Roll":"${data.dice*}",
"Fortune":"${data.fortune*}",
"Luck Today":"${data.luck*}"
}
scheduleEnabled: true
schedules: []
sequence:
commands:
- description: roll dice
exec: echo $(($RANDOM % 6 + 1 ))
plugins:
LogFilter:
- config:
invalidKeyPattern: \s|\$|\{|\}|\\
logData: 'true'
name: dice
regex: ^(.+)$
type: key-value-data
- description: fortune
exec: /usr/games/fortune
plugins:
LogFilter:
- config:
hideOutput: 'false'
logData: 'false'
name: fortune
regex: (.+?)
type: key-value-data-multilines
- description: wishing
exec: RD_COLOR=0 rd pond
plugins:
LogFilter:
- config:
invalidKeyPattern: \s|\$|\{|\}|\\
logData: 'false'
name: luck
regex: ^(.+\.)$
type: key-value-data
- configuration:
debugOnly: 'false'
nodeStep: false
type: log-data-step
keepgoing: false
strategy: node-first