Scaling Rundeck
This guide explains approaches and implementation examples for making Rundeck highly available and scaling Rundeck for production use. Rundeck is a Java webapp so many of the HA and scaling approaches will be similar to beefing up those kinds of applications in general. At this time, there is not a standard HA/Cluster configuration. The approaches discussed here are based on practices shared to us through our community. Use the approaches as guidelines to create your own solution.
Overview
When thinking about scaling Rundeck there are roughly two concerns:
- Make an individual Rundeck perform better. To tune an individual Rundeck instance see the Tuning Rundeck page. Also see the Database section below. Use an external database service like Mysql.
- Make the service you are providing with Rundeck handle more users and bigger workloads by adding more machines for increased capacity. In this case, you either want to be sure Rundeck is highly available or you want to add more capacity to serve more users or processing.
Installation types
There are two types of Rundeck installations:
- standalone: This installation includes the embedded Jetty container. If you installed the RPM/DEB or launcher.jar, this is a standalone.
- WAR deployment: This installation deploys the Rundeck application via a WAR into a container like Apache-Tomcat.
Depending on your installation preference, either is viable but there are pros and cons, too.
The advantage of the standalone installation is convenience and simplicity. The standalone install defines a set of conventions about install locations and environment. The downside of the standalone installation is it can be more opaque to manage and control the internal Jetty container.
The advantage of a WAR deployment is greater managability of the container, of course. If you have a standard container for your organization, chances are there is already tooling for managing an HA failover process, balancing load across multiple instances, monitoring the webapps, and controlling the container as a service. The downside to the WAR deployment is that it might be less convenient to install for new users. They will have to install the container, drop in the WAR and then configure the webapp.
Using either install, the goal is to create a high performing and available production Rundeck.
Finally, if you are reading this chapter you are no doubt putting Rundeck into an important production role. Therefore, it is important that you also have backup and restore, monitoring and ops support to manage your Rundeck installations. It's a key service.
Known shortcomings and caveats
The Rundeck project is in its early stages for building a complete HA and clustering solution. We are identifying HA and Clustering requirements and adding them to our roadmap. If these features are important to you we encourage you to vote on them or comment!
- No checkpoint restart: Jobs that terminate during mid-execution due to the primary failure are not resumable from the last step. The plan is to implement an execution model that is stored in the database. The model will contain a complete graph of steps of execution and progress.
- No automated job resumption: When the primary takes over, it does not automatically re-run jobs that failed due to the server failure. The plan is to use the checkpoint restart capability to flag jobs that could be resumed and put them in a special job group.
- No "passive mode": Disable job execution from a rundeck instance to make it act like a true passive server. The work around has been to have an ACL policy meant for passive mode which disallows all job execution.
- No API to manage configuration: Sometimes an HA primary or cluster members need their configuration modified to customize their role or environment. This must currently be done using an external tool.
Performance
Increasing performance is generally done using a "divide and conquer" strategy wherein various non job related processing is offloaded from the Rundeck webapp.
Database
Don't use the embedded database. If you install the vanilla standalone rundeck configuration, it will use an embedded database. Rundeck versions prior to 1.5, use the Hypersonic database (HSQLDB). Versions 1.5 and beyond include the H2 database. Either HSQLDB or H2 has a low performance wall. Rundeck users will hit this limitation at a small-medium level of scale.
For high performance and scale requirements, you should not use these embedded databases. Instead, use an external database service like Mysql or Oracle. See the Setting up an RDB Datasource page to learn how to configure the Rundeck datasource to your database of choice.
Also, be sure to locate your external database on a host(s) with sufficient capacity and performance. Don't create a downstream bottleneck!
Node execution
If you are executing commands across many hundreds or thousands of hosts, the bundled SSH node executor may not meet your performance requirements. Each SSH connection uses multiple threads and the encryption/decryption of messages uses CPU cycles and memory. Depending on your environment, you might choose another Node executor like MCollective, Salt or something similar. This essentially delegates remote execution to another tool designed for asynchronous fan out and thus relieving Rundeck of managing remote task execution.
Built in SSH plugins
If you are interested in using the built in SSH plugins, here are some details about how it performs when executing commands across very large numbers of nodes. For these tests, Rundeck was running on an 8 core, 32GB RAM m2.4xlarge AWS EC2 instance.
We chose the rpm -q command which checks against the rpm database to see if a particular package was installed. For 1000 nodes we saw an average execution of 52 seconds. A 4000 node cluster took roughly 3.5 minutes, and 8000 node cluster about 7 minutes.
The main limitation appears to be memory of the JVM instance relative to the number of concurrent requests. We tuned the max memory to be 12GB with a 1000 Concurrent Dispatch Threads to 1GB of Memory. GC appears to behave well during the runs given the "bursty" nature of them.
SSL and HTTPS performance
It is possible to offload SSL connection processing by using an SSL termination proxy. This can be accomplished by setting up Apache httpd or Nginx as a frontend to your Rundeck instances.
Resource provider
Rundeck projects obtain information about nodes via a resource provider. If your resource provider is a long blocking process (due to slow responses from a backend service), it can slow down or even hang up Rundeck. Be sure to make your resource provider work asynchronously. Also, consider using caching when possible.
Failover
Rundeck failover can be achieved with an Active/Standby cluster configuration. The idea is to have two instances of Rundeck, a primary actively handling traffic while a standby Rundeck passively waits to take the primary's place when the primary becomes unavailable.
The process of taking the active primary role is called failover or takeover. The takeover procedure is generally a multi-step one, involving taking over job schedules, notifiying monitoring and administrators, updating naming services, and any custom steps needed for your environment.
Depending on your service level availability requirements, the failover process might be done automatically within seconds or the process might go through an Ops escalation and be done in minutes.
Database
To support failover, a shared external database service must be used. Each rundeck instance must be configured to connect to the common database instance. A Rundeck HA solution also depends on a database replication scheme.
Database Replication is a software solution that enables the user to replicate the Rundeck database tables to another database. The term master is used to describe the instance of the database that is being updated. Replication can either be to a Standby database or to members of a database cluster solution.
AWS users might consider using RDS as highly available Mysql database.
Standby database
The configuration consists of two database servers; one is the primary database server and the other is in a standby mode. The primary server distributes its log files to the standby machine that can apply the changes immediately or not, based on the configuration. The detection of a failure and the failover procedure is a series of steps that can be operated manually or contained in a script that can be run automatically by the system that monitors the database. After the failover, which causes some inevitable downtime, the standby database will function as the main database server. Returning to the original database server is not a one-step process.
Database Cluster solution
Oracle, Mysql, and MS-SQL offer solutions to enable activation of multiple SQL servers over the cluster nodes. These solutions (e.g., Oracle RAC Parallel Server) provide transparency to Rundeck during the failover process by taking over the database session of the failed node in a way that is transparent to the Rundeck servers.
Log store
An HA Rundeck requires Rundeck instances share the same log store. Job execution output is stored locally to the Rundeck instance that ran the job but this output can be loaded into a common storage facility (eg, AWS S3, WebDAV, custom). See Logging Plugin Development to learn how to implement your own log storage. Of course, you can configure your Rundeck instances to share a file system using a NAS/SAN or NFS but those methods are typically less desirable or impossible in a cloud environment. Without a shared logstore, job output files would need to be synchronized across Rundecks via a tool like rsync.
With a configured Log store, the executing Rundeck instance copies the local output file to the log store after job completion. If the standby rundeck instance is activated, any request for that output log will cause the standby to retrieve it from the log store and copy it locally for future acccess.
Rundeck will make multiple attempts to store a log file if the logstore is unavailable.
Note, like the database, logstores should also be replicated and available. For an AWS environment, S3 serves as a highly available and scalable log store.
HA monitor
An HA monitor is a mechanism used to check the availability of the primary Rundeck and initiate the takeover for the standby Rundeck. This generally assumes that clients connect to the primary Rundeck using a DNS name or virtual IP address. This avoids having to communicate the address of the active Rundeck instance to users in case of a failover.
Health check
The HA monitor should be configured to run a health check to test the status of the primary. It's important not to cause a takeover unless you are certain it needs to be done! Here are several health tests to consider:
- Reachable: Ping the primary Rundeck to be sure it's reachable over the network.
- API connection: Connect to the rundeck instance and get its system info. See: /api/1/system/info.
- Custom: You might also script a check unique to your configuration and environment.
A health check should be designed to take the following parameters:
- maxtries: Number of attempts to run the health check (eg 3).
- interval: Amount of time to check in between tries (eg 30sec).
- timeout: Amount of time to wait for a check before failing because it exceeded the timeout (eg, 30sec).
Writing the health check to test various levels of access can also assist in narrowing down the cause of the unavailability.
Takeover
The takeover procedure should include any steps to make the standby a fully functioning primary rundeck instance. Here are some steps to consider in your takeover procedure:
- Scheduled jobs that were managed by the primary must be taken over by the secondary. See the takeover schedule API.
- Update the monitoring station to start checking the new primary (old secondary).
- Update other maintenance tools that need care for the primary (eg, backup, cleanup).
- Optionally, provision a new secondary instance.
Solutions
The HA monitor can be implemented in a number of ways depending on the level of sophistication and automation required:
- Proxy/Loadbalancer
The primary and standby rundeck instances sit behind a proxy (eg, Apache mod_proxy, mod_jk, HA proxy) or a load balancer (eg, F5, AWS ELB). The proxy/loadbalancer perform the health check and direct traffic to the active primary rundeck instance using a virtual IP address. This method is the most seamless to end-users and typically the quickest and most automated.
- Scripted
This approach uses several scripts to perform the check and takover procedures (monitor, check, takeover). The "monitor" script is the main driver which periodiclly runs the "check" script which performs the various levels of health tests. When the check script detects the primary is down, the monitor script invokes the "takeover" script. The scripts can be run from the standby Rundeck server or from an adminstrative station.
- Monitoring station
Similar to the scripted approach, a monitoring station such as Nagios or Zabbix acts as the HA monitor and runs the check and takeover scripts. It may also coordinate updating DNS or VIP entries.
Clustering and horizontal scaling
To provide more capacity for growing numbers of users or job executions, Rundeck can be deployed using a horizontal scaling (or scale out) approach. Using this approach, independent Rundeck instances run in different machines. Requests can be served by any machine transparently. Clustering requirements build on some of the needs as HA solutions. This specifically includes: a load-balancing proxy front end and a shared database and logstore.
Generally, the architecture is composed of the following units:
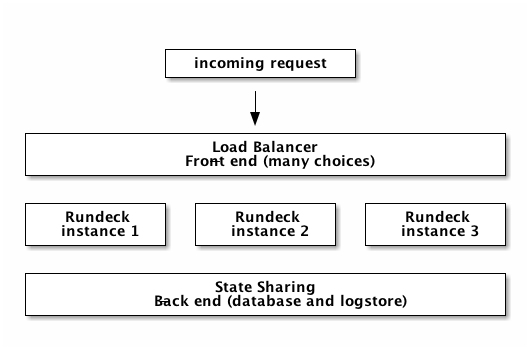
Clustering architecture
Examples
Several examples of clustering and HA are included below. The Amazon example represents what can be done in a cloud environment. The Apache-Tomcat cluster example reflects what users have done in datacenter environments. Finally, some users have implemented their own solutions using basic methods and Rundeck itself.
Amazon Cloud
A scalable and available Rundeck service can be created using the standalone Rundeck installation and common Amazon web services.
A very large SaaS company uses Rundeck as a backend service within a suite of cloud operations tools. Users access Rundeck indirectly via a specialized graphic interface which more or less is a pass through, calling various Rundeck WebAPI methods. Because these cloud operations tools must support both developers, testers and ops teams around the world, the Rundeck service must be highly available.
The following frontend and backend services are used in conjunction with Rundeck:
- Load balancer: Elastic load balancer (sticky session, SSL terminator)
- Database: RDS (Mysql instance)
- Log store: S3 using the S3 log plugin
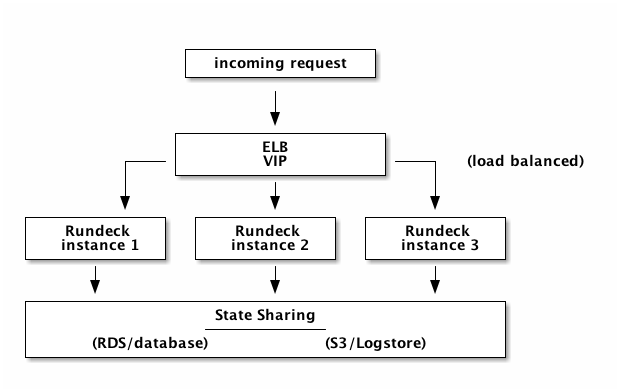
Clustering architecture
Note, if all your deployments run in EC2, you might also consider using the EC2 nodes plugin so Rundeck knows about your EC2 instances.
Apache-Tomcat Cluster
One of Rundeck's largest deployments is based on Tomcat clusters, Oracle RAC and a SAN logstore. This configuration uses two pairs of 2 node clusters in two data centers. Each cluster is load balanced using an F5 with a GLB managing failover across data centers. Each Rundeck project supports a particular line of business, with each customer environment containing dozens to small hundreds of hosts. Each user has a login to the Rundeck GUI and conducts the work through the console. This Rundeck service supports 500 users in over 200 projects and 10,000 job executions a month.
If Oracle RAC and SAN storage is not available to you, here's a similar architecture using Mysql and a WebDAV store:
- Apache httpd/mod_jk2: Apache module provides integration between Apache web server and Tomcat.
- Apache httpd/mod_dav: Apache module provides provides a WebDAV service. (see webdav-logstore-plugin)
- Coyote AJP: Provides communication channel between Apache and the Rundeck instances in Tomcat.
- Sticky sessions: Ensures incoming requests with same session are routed to the same Tomcat worker. This does not use session sharing/replication.
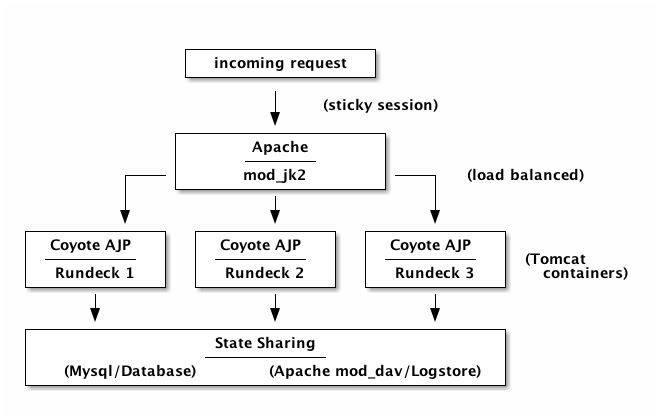
Apache-tomcat cluster
Simple HA failover
This last example is basically a "roll your own" HA failover solution that uses the scripted methods described earlier. This example uses the monitor, check, takeover scripts to perform the health tests, synchronize configuration and take over the primary role, if the primary is detected as down. The example, assumes there is a load balancer and an associated VIP to manage the traffic redirection. A sync job is used to replicate rundeck configuration across instances.
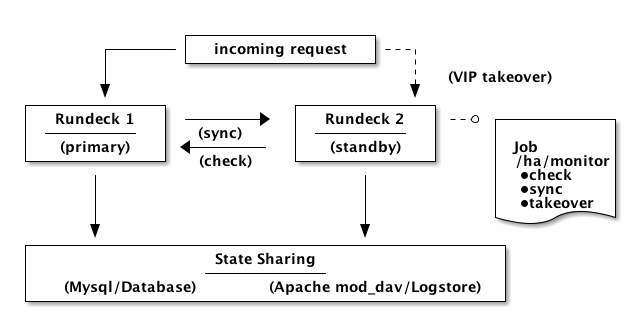
Simple HA failover
If you are curious to see an example of a simple HA failover setup, take a look at this multi-node Vagrant configuration: primary-secondary-failover.
Let us know if you develop your own HA failover solution.