Template Job: Recent Pod logs and Kubernetes Events
Automated Diagnostics
Template Job: Recent Pod logs and Kubernetes Events
When an issue arises with applications deployed in Kubernetes, one of the first common actions taken by engineers is to check the health of Pods. If any pods are "unhealthy," then the engineer will look at recent logs and Kubernetes Events pertaining to the unhealthy pods.
To do this troubleshooting effectively not only requires the right set of permissions, but also involves multiple commands that require a decent familiarity with Kubernetes.
Here is an example Job that retrieves recent Pod logs and Kubernetes events - specifically for unhealthy pods - using kubectl: Below is an exmaple Job Definition. Copy and paste the contents into a file and import the Job to your Automation instance.
- defaultTab: nodes
description: ''
executionEnabled: true
group: E-Commerce K8s
id: e1e2f075-8e10-4f67-8721-5171fcb6af3c
loglevel: INFO
name: Retrieve All Unhealthy Containers
nodeFilterEditable: false
options:
- description: The number of lines of recent logs to print from failed pods.
enforced: true
label: Number of Log Lines
name: log-lines
value: '5'
values:
- '5'
- '10'
- '20'
- '50'
- '100'
valuesListDelimiter: ','
- description: Namespace to search for unhealthy pods.
label: Kubernetes Namespace
name: namespace
value: default
plugins:
ExecutionLifecycle: {}
scheduleEnabled: true
schedules: []
sequence:
commands:
- plugins:
LogFilter:
- config:
mode: bold
regex: '(Events for pod: .*)'
type: highlight-output
- config:
mode: bold
regex: '(Recent logs for pod: .*)'
type: highlight-output
script: "crashloop_pods=$(kubectl get pods -n @option.namespace@ --no-headers\
\ -o custom-columns=':metadata.name,:status.containerStatuses[*].state.waiting.reason'\
\ | grep -v \"\\<none\\>\")\n\nfor crashLoopPod in $crashloop_pods\ndo\n \
\ if [ \"$crashLoopPod\" != \"CrashLoopBackOff\" ];\n then\n echo\
\ \"Events for pod:\" $crashLoopPod\n kubectl get event -n @option.namespace@\
\ --field-selector involvedObject.name=$crashLoopPod\n \n echo\
\ \"Recent logs for pod:\" $crashLoopPod\n kubectl logs -n @option.namespace@\
\ $crashLoopPod --tail=@option.log-lines@\n echo \"\\n\"\n fi\n\
done\n\nerror_pods=$(kubectl get pods -n @option.namespace@ --field-selector=status.phase!=Running\
\ --no-headers -o custom-columns=\":metadata.name\" | grep -v Completed)\n\
\nfor errorPod in $error_pods\ndo\n echo \"Events for pod:\" $errorPod\n\
\ kubectl get event -n @option.namespace@ --field-selector involvedObject.name=$errorPod\n\
\ \n echo \"Recent logs for pod:\" $errorPod\n kubectl logs -n @option.namespace@\
\ $errorPod --tail=@option.log-lines@\n echo \"\\n\"\ndone\n"
keepgoing: false
strategy: node-first
uuid: e1e2f075-8e10-4f67-8721-5171fcb6af3c
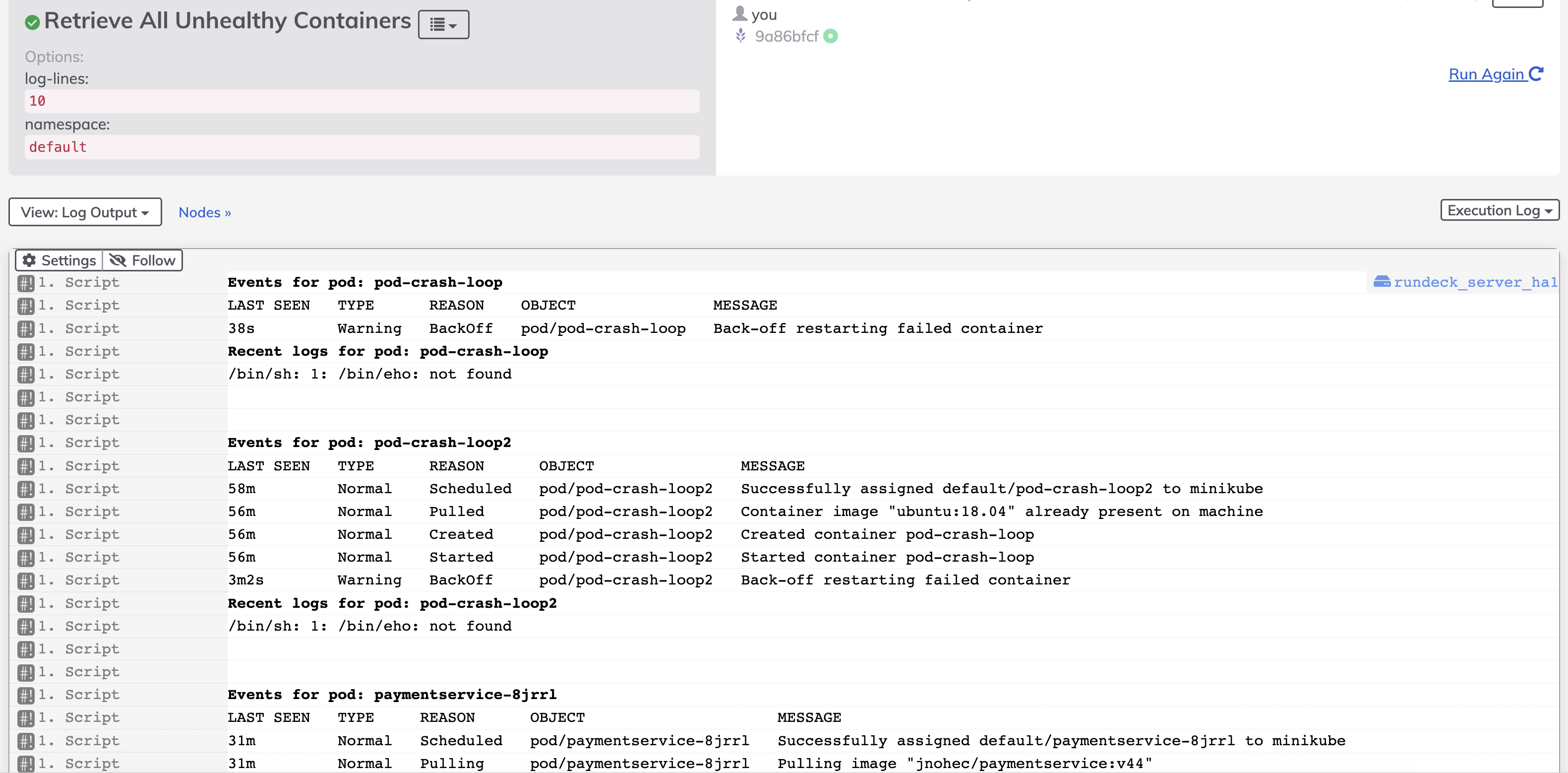
Here is the example Output from the job definition above.